Rocking with Flink on a Zeppelin
I recently started to use Apache Zeppelin, because I wanted a tool that allows me to work with notebooks using Scala + Apache Flink and as a plus, Apache Zeppelin provides you with autogenerated plots if you print you data as TSV file !!!!!!!
%table
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 t14
1 2 3 4 5 0 0 0 0 0 0 0 0 0 0
1 1 2 3 4 5 0 0 0 0 0 0 0 0 0
1 2 2 2 3 4 4 5 0 0 0 0 0 0 0
1 3 4 5 0 0 0 0 0 0 0 0 0 0 0
1 1 1 2 2 2 3 3 3 4 4 4 5 5 5
1 1 2 3 1 4 5 0 0 0 0 0 0 0 0
1 2 3 1 1 4 5 0 0 0 0 0 0 0 0
1 5 3 2 4 0 0 0 0 0 0 0 0 0 0
1 5 5 3 2 1 4 0 0 0 0 0 0 0 0
1 5 5 3 5 1 4 2 0 0 0 0 0 0 0
2 3 3 3 4 5 1 0 0 0 0 0 0 0 0
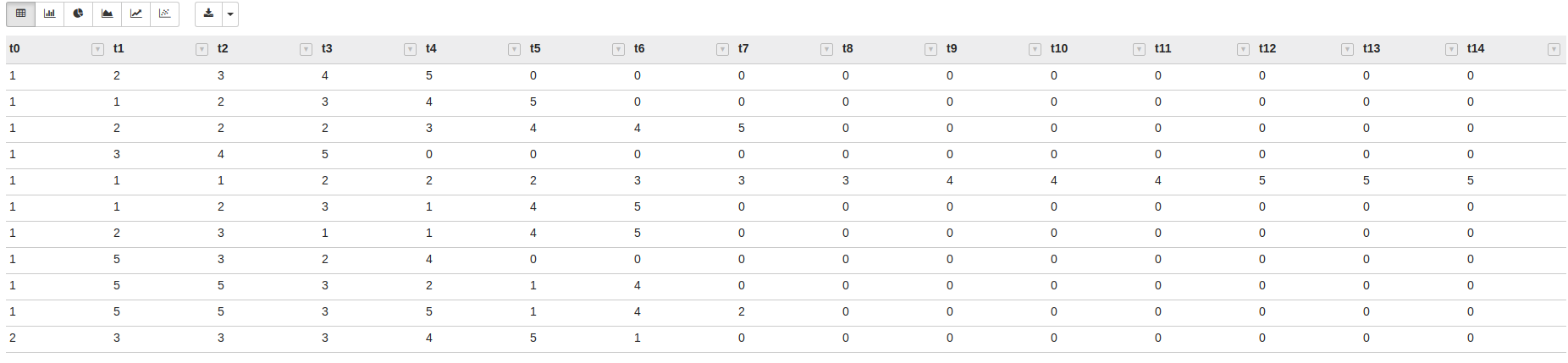
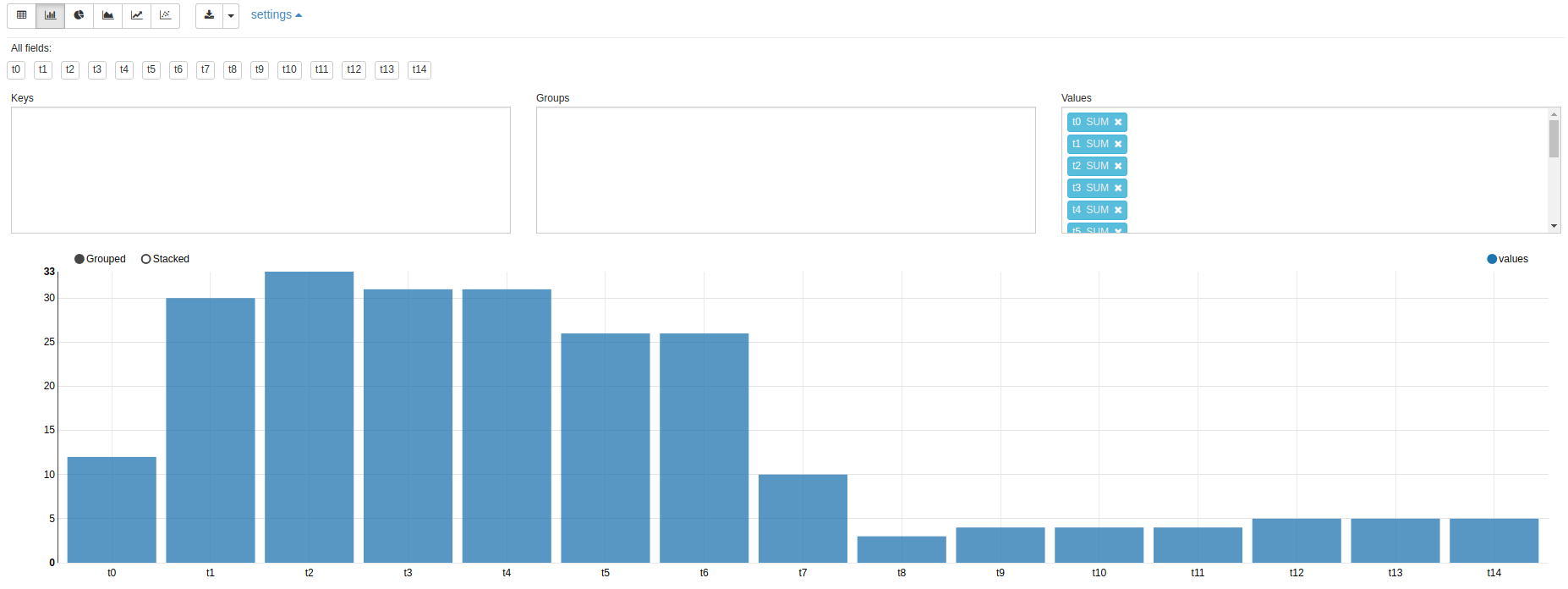
If you print your data inside a notebook paragraph it will automatically allow you to do scatter plots, bar plots, pie charts, etc. and c’mon that’s freaking amazing, you don’t have to write you data in a DB/File/Thing and then plot the data using other tools, so you can have all your work in a single place and that’s nice.
So, if everything is nice, what am I doing here writting all this? By default, Zeppelin brings a Flink interpreter that you can use to run Flink workloads and when you execute it for the first time, it will start a Flink local minicluster in wich Zeppelin will run your workload and that’s great if you are doing small tests, but when the problem scales a bit that cluster isn’t enough. Also the Flink minicluster that brings Zeppelin is running Flink 1.1.3 and Flink 1.5 it’s already out. The sad part about this, it that i only had time to make it run with Flink 1.4.2, because until that version Flink’s jobs could be sended using an RPC port Job Manager’s port 6123, but since that version jobs should be sended using Flink’s REST API, so Zeppelin’s interpreter should be patched to use the REST API.
Creating our environmet
Let’s get dirty and start to work a bit on all this, first of all we need to create the environment that we want to use, in this case it will be a Zeppelin Notebook Server, a Flink node running a Jobmanagar and two Flink nodes running Taskmanagers. With this in mind I’ve made the following docker-compose file:
version: "3"
services:
#=============================
# FLINK
#=============================
jobmanager:
image: flink:1.4.2
expose:
- "6123"
ports:
- "6123:6123"
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: flink:1.4.2
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
#=============================
# ZEPPELIN
#=============================
zeppelin:
image: apache/zeppelin:0.7.3
ports:
- "8080:8080"
Once we have this docker-compose file we can create our environment running the following docker-compose command
docker-compose up -d --scale taskmanager=2
So our environment should look like this:
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------
zeppelinflink15_jobmanager_1 /docker-entrypoint.sh jobm ... Up 0.0.0.0:6123->6123/tcp, 0.0.0.0:8081->8081/tcp
zeppelinflink15_taskmanager_1 /docker-entrypoint.sh task ... Up 6121/tcp, 6122/tcp, 6123/tcp, 8081/tcp
zeppelinflink15_taskmanager_2 /docker-entrypoint.sh task ... Up 6121/tcp, 6122/tcp, 6123/tcp, 8081/tcp
zeppelinflink15_zeppelin_1 /usr/bin/tini -- bin/zeppe ... Up 0.0.0.0:8080->8080/tcp
NOTE: my containers start with the prefix 'zeppelinflink15' because thats the name of the folder in which im working
If we access to http://localhost:8080 we should have access to zeppeling UI
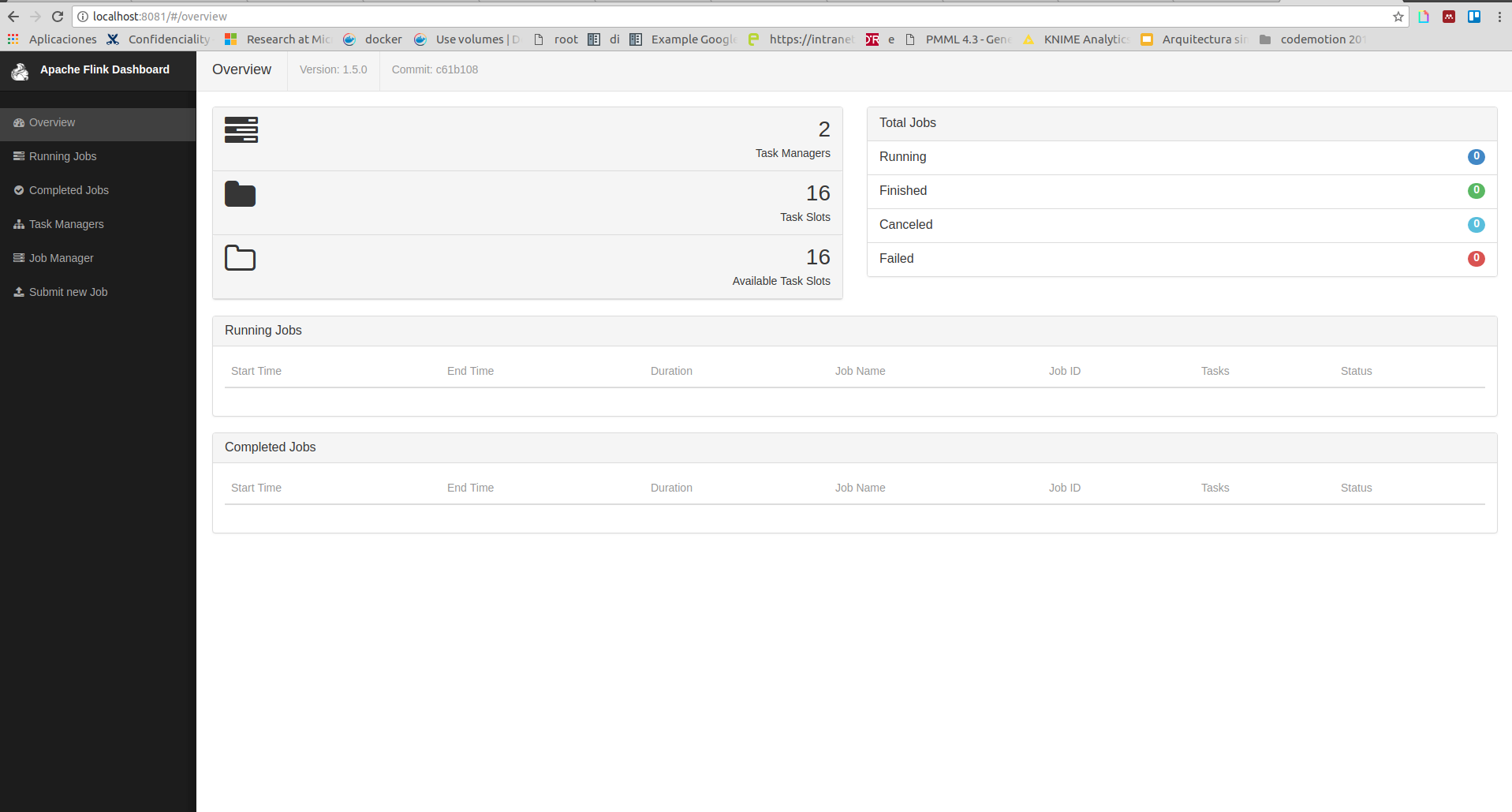
And if we access to http://localhost:8081 we should be able to see Flink’s Web UI
Setting up the environment
Once we have all the parts that we need, the next step is to configure Zeppelin to use our Flink cluster when we run a paragraph of code with the flink interpreter %flink. For this, we need to go to the interpreters section inside Zeppelin UI and find the Flink interpreter %flink
Before changing anything in the interpreter I want to show you which libraries contains that interpreter, to understand wich changes we are gonna do. So let’s connect to the Zeppelin container that we have created with docker-compose using:
NOTE: to obtain the name of the Zeppelin container use sudo docker-compose ps
docker exec -it zeppelinflink15_zeppelin_1 /bin/bash
Once inside the container we can run the following command to check the dependencies that is using the Flink interpreter
ls interpreter/flink/
activation-1.1.jar
akka-actor_2.11-2.3.7.jar
akka-remote_2.11-2.3.7.jar
akka-slf4j_2.11-2.3.7.jar
akka-testkit_2.11-2.3.7.jar
aopalliance-1.0.jar
avro-1.7.6.jar
chill_2.11-0.7.4.jar
chill-java-0.7.4.jar
commons-beanutils-bean-collections-1.8.3.jar
commons-cli-1.3.1.jar
commons-codec-1.5.jar
commons-collections-3.2.1.jar
commons-compress-1.4.1.jar
commons-configuration-1.9.jar
commons-daemon-1.0.13.jar
commons-digester-1.8.1.jar
commons-el-1.0.jar
commons-io-2.4.jar
commons-lang-2.5.jar
commons-lang3-3.3.2.jar
commons-logging-1.1.1.jar
commons-math3-3.5.jar
commons-net-3.1.jar
config-1.2.1.jar
flink-annotations-1.1.3.jar
flink-clients_2.11-1.1.3.jar
flink-core-1.1.3.jar
flink-java-1.1.3.jar
flink-metrics-core-1.1.3.jar
flink-optimizer_2.11-1.1.3.jar
flink-runtime_2.11-1.1.3.jar
flink-scala_2.11-1.1.3.jar
flink-scala-shell_2.11-1.1.3.jar
flink-shaded-hadoop2-1.1.3.jar
flink-streaming-java_2.11-1.1.3.jar
flink-streaming-scala_2.11-1.1.3.jar
force-shading-1.1.3.jar
grizzled-slf4j_2.11-1.0.2.jar
gson-2.2.jar
guice-3.0.jar
jackson-annotations-2.4.0.jar
jackson-core-2.4.2.jar
jackson-core-asl-1.9.13.jar
jackson-databind-2.4.2.jar
jackson-mapper-asl-1.9.13.jar
javassist-3.18.2-GA.jar
javax.inject-1.jar
java-xmlbuilder-0.4.jar
jaxb-api-2.2.2.jar
jersey-core-1.9.jar
jetty-util-6.1.26.jar
jline-0.9.94.jar
jsch-0.1.42.jar
jsr305-1.3.9.jar
kryo-2.24.0.jar
log4j-1.2.17.jar
metrics-core-3.1.0.jar
metrics-json-3.1.0.jar
metrics-jvm-3.1.0.jar
minlog-1.2.jar
netty-3.8.0.Final.jar
netty-all-4.0.27.Final.jar
objenesis-2.1.jar
org.apache.sling.commons.json-2.0.6.jar
paranamer-2.3.jar
protobuf-java-2.5.0.jar
scala-compiler-2.11.7.jar
scala-library-2.11.7.jar
scala-parser-combinators_2.11-1.0.4.jar
scala-reflect-2.11.7.jar
scala-xml_2.11-1.0.4.jar
scopt_2.11-3.2.0.jar
servlet-api-2.5.jar
slf4j-api-1.7.10.jar
slf4j-log4j12-1.7.10.jar
snappy-java-1.0.5.jar
stax-api-1.0-2.jar
uncommons-maths-1.2.2a.jar
xmlenc-0.52.jar
xz-1.0.jar
zeppelin-flink_2.11-0.7.3.jar
zookeeper-3.4.6.jar
And in all that mess we can see that it is using Flink 1.1.3 for Scala 2.11:
ls interpreter/flink/ | grep "flink"
flink-annotations-1.1.3.jar
flink-clients_2.11-1.1.3.jar
flink-core-1.1.3.jar
flink-java-1.1.3.jar
flink-metrics-core-1.1.3.jar
flink-optimizer_2.11-1.1.3.jar
flink-runtime_2.11-1.1.3.jar
flink-scala_2.11-1.1.3.jar
flink-scala-shell_2.11-1.1.3.jar
flink-shaded-hadoop2-1.1.3.jar
flink-streaming-java_2.11-1.1.3.jar
flink-streaming-scala_2.11-1.1.3.jar
zeppelin-flink_2.11-0.7.3.jar
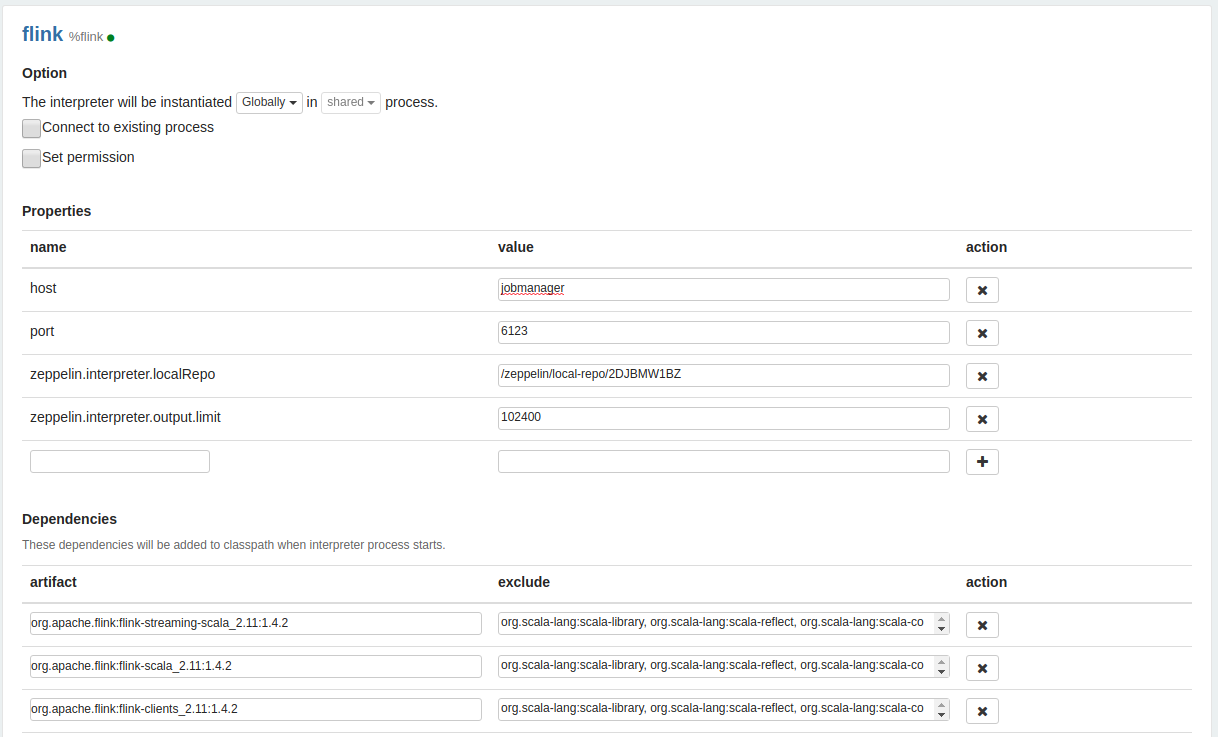
Now that we have ensured ourselves that we don’t have compatible libraries for our Flink Cluster, we have to add them to the interpreter in some way. I have choose to edit the flink interpreter using the UI and add the following dependencies supressing the Scala classes because we already have that libs loaded in the interpreter.
NOTE: the dependencies will be downloaded from mvn central repository
| artifact | exclude |
|---|---|
| org.apache.flink:flink-streaming-scala_2.11:1.4.2 | org.scala-lang:scala-library,org.scala-lang:scala-reflect,org.scala-lang:scala-compiler |
| org.apache.flink:flink-scala_2.11:1.4.2 | org.scala-lang:scala-library,org.scala-lang:scala-reflect,org.scala-lang:scala-compiler |
| org.apache.flink:flink-clients_2.11:1.4.2 | org.scala-lang:scala-library,org.scala-lang:scala-reflect,org.scala-lang:scala-compiler |
And I have also changed the property host of the interpreter from local to jobmanager, with this change the Flink interpreter will access to the container inside our docker-compose, named as Jobmanager, instead of start a new Flink mini cluster when we run a Flink paragraph.
Image with all changes made
Testing
With all changes made, now you should be able to run the following piece of code inside your Flink interpreter on top of your Flink cluster.
val dataset = benv.fromCollection(List(
Array(1,2,3,4,5,0,0,0,0,0,0,0,0,0,0),
Array(1,1,2,3,4,5,0,0,0,0,0,0,0,0,0),
Array(1,2,2,2,3,4,4,5,0,0,0,0,0,0,0),
Array(1,3,4,5,0,0,0,0,0,0,0,0,0,0,0),
Array(1,1,1,2,2,2,3,3,3,4,4,4,5,5,5),
Array(1,1,2,3,1,4,5,0,0,0,0,0,0,0,0),
Array(1,2,3,1,1,4,5,0,0,0,0,0,0,0,0),
Array(1,5,3,2,4,0,0,0,0,0,0,0,0,0,0),
Array(1,5,5,3,2,1,4,0,0,0,0,0,0,0,0),
Array(1,5,5,3,5,1,4,2,0,0,0,0,0,0,0),
Array(2,3,3,3,4,5,1,0,0,0,0,0,0,0,0)
)
)
val results = dataset.collect()
var table = "%table\n"
table += "t0 \t t1 \t t2 \t t3 \t t4 \t t5 \t t6 \t t7 \t t8 \t t9 \t t10 \t t11 \t t12 \t t13 \t t14 \n"
for(result <- results){
for(item <- result){
table += item + "\t"
}
table += "\n"
}
println(table)
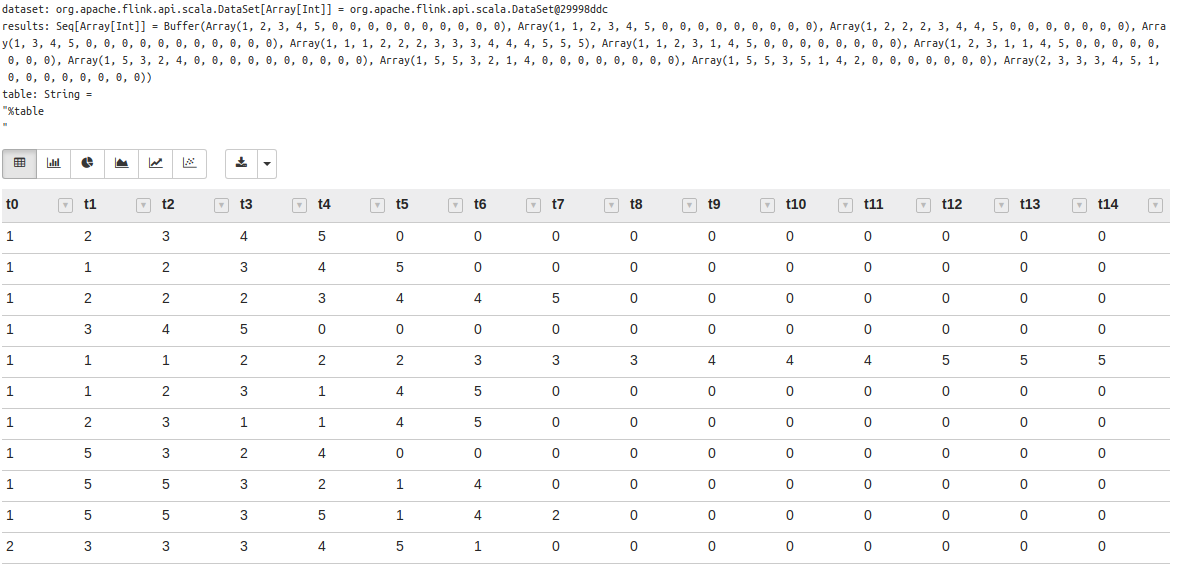
For that piece of code you should have the following output without any errors:
And that’s all, I hope that this post could be helpful for those working with Apache Zeppelin and Apache Flink and you can ping me on twitter @diegoreico if you want to talk about something related to this.